清华团队:具身世界模型综述绘就通用智能体发展技术新蓝图
Sep 20, 2025近日,清华大学电子工程系城市科学与计算研究中心发布了一篇关于具身世界模型(Embodied World Models) 的系统性综述论文,首次从模型架构、训练方法、应用场景与评估体系等多个维度,对该领域的关键技术进行了全面梳理与分类。研究不仅追溯了世界模型从心理学起源到人工智能实现的发展历程,还提出了一个以基模架构、训练范式、应用场景与评测体系为核心的技术分类框架,并对未来研究方向进行展望,为构建面向通用人工智能(AGI)的具身世界模型提供了综合的技术路线图。
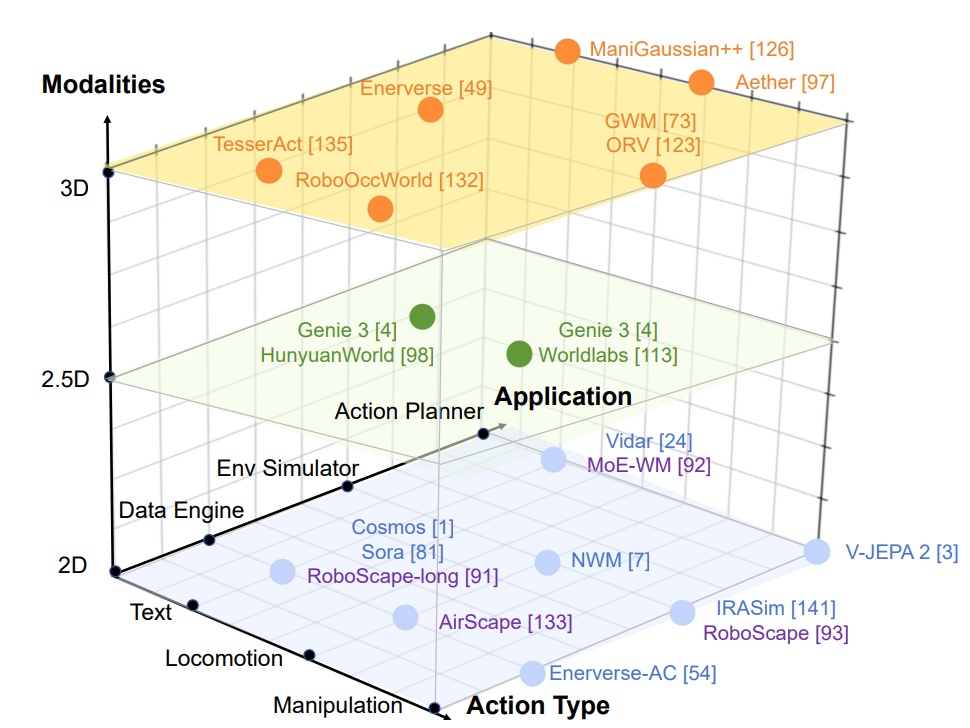
图1 基于生成模态、动作类型、应用方式的世界模型分类体系
世界模型旨在为智能体构建环境状态表示并预测其动态变化,这一概念源于认知心理学中关于假设性思维的研究。自2018年Ha等人提出首个融合感知压缩与动态建模的强化学习世界模型以来,该类方法迅速成为人工智能领域的研究热点。随着生成式人工智能技术的突破,以Genie、Worldlabs为代表的交互式视觉生成模型,展现出卓越的场景生成与状态预测能力,已成为世界模型的重要实现范式。与此同时,以JEPA为代表的潜在空间建模方法,致力于在抽象表征空间中实现高效行为推理,形成与之并行发展的技术路线。二者各自的优势与融合潜力,仍有待进一步探索。
目前,世界模型的研究多集中于游戏仿真与自动驾驶等场景,而面向机器人等具身智能体的物理世界建模仍处于早期阶段。构建能够模拟物理规则、支持复杂交互的具身世界模型,被视为实现具身通用人工智能的关键路径。此类模型的核心优势体现在两方面:一是通过对环境动态的显式建模,支持智能体在真实场景中进行长程规划,克服传统模仿学习的局限;二是通过提炼通用世界先验,显著增强模型在分布外场景下的泛化能力,使其能够快速适应未知任务与环境。
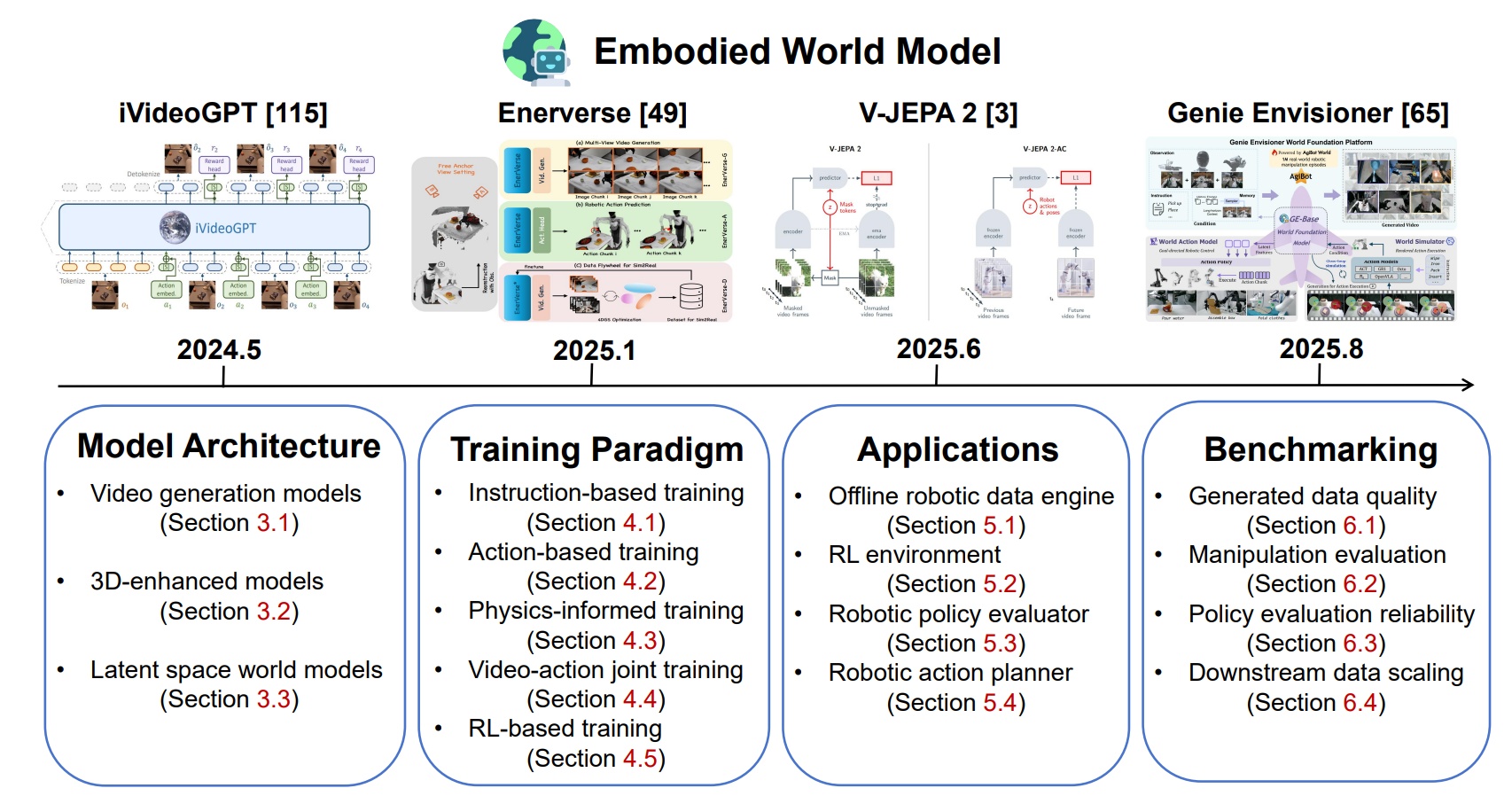
图2 以模型架构、训练范式、应用场景与评估体系为核心的具身世界模型分类框架
在技术架构方面,现有具身世界模型可分为三类:基于视频生成的世界模型、融合三维重建的世界模型,和以压缩表征为核心的潜在世界模型。训练方法多采用以外部指令(如文本指令或动作轨迹)为控制条件的生成范式。近年来,视觉-动作联合预测框架与物理约束学习机制等新范式也逐渐兴起,进一步提升了模型的动作理解能力与物理一致性。
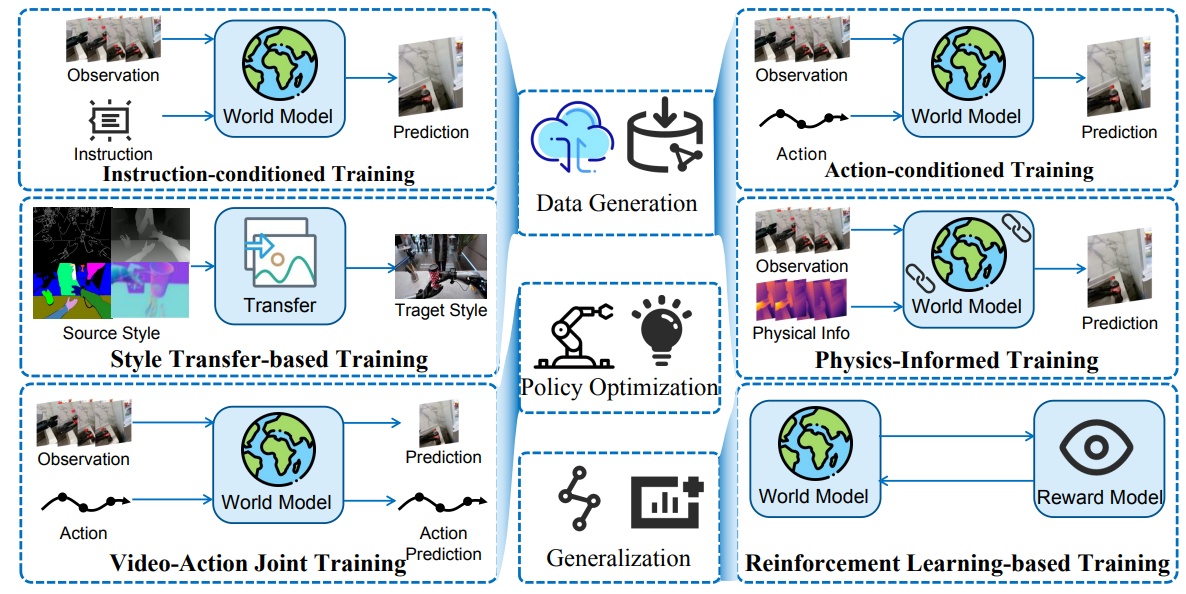
图3 具身世界模型训练范式分类框架
在应用层面,具身世界模型主要承担三类职能:作为云端数据合成引擎,生成高质量仿真数据以训练视觉-语言-动作模型(VLA);作为环境代理,在仿真系统中评估与训练具身智能体;以及作为机器人的“大脑”,通过实时状态推理支持行动决策。
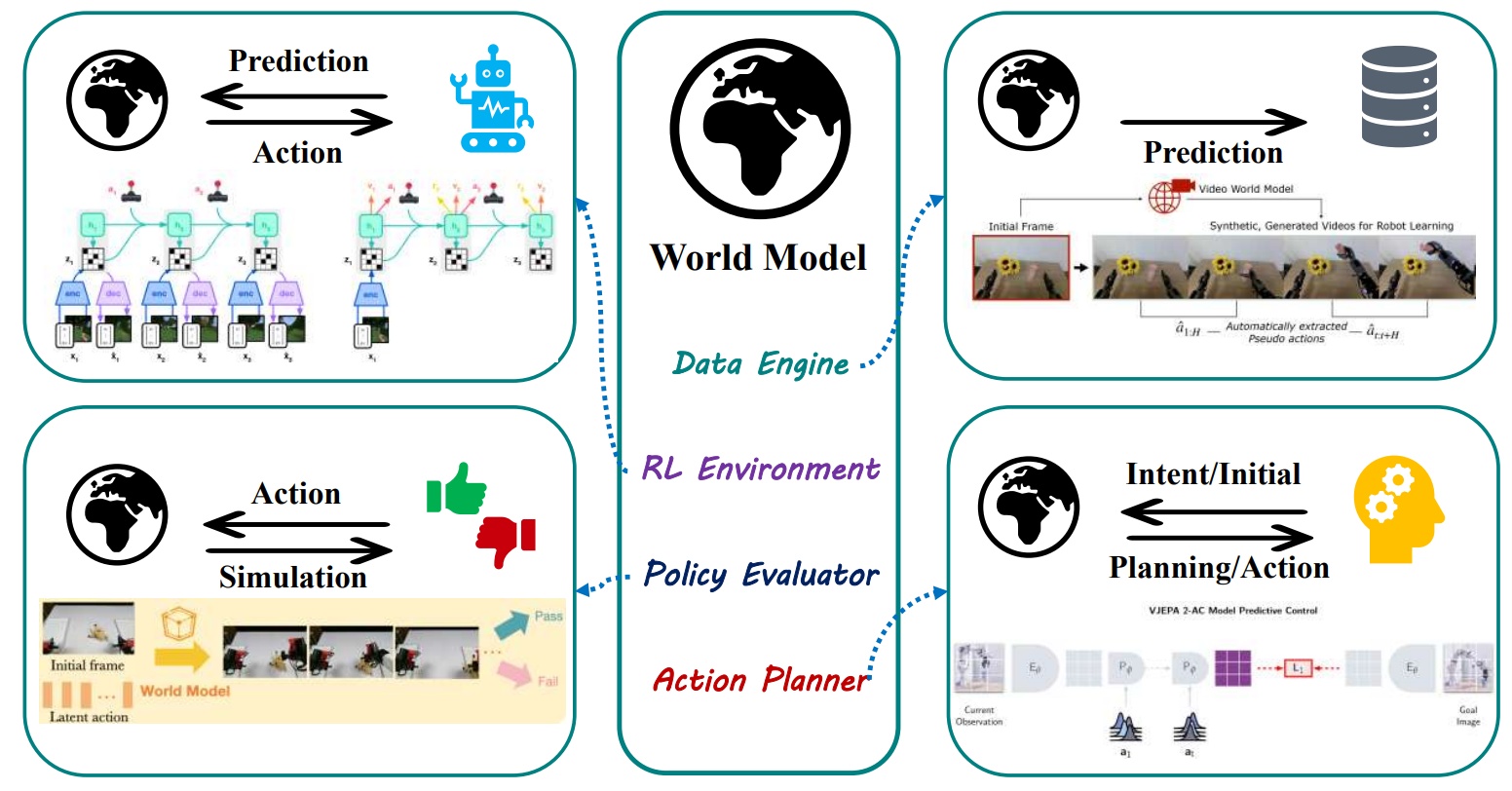
图4 具身世界模型应用场景分类
在评估方面,综述指出四种对具身世界模型的评测视角,一是生成数据质量评估,包含视觉质量、物理规律遵从性等;二是面向端到端行动的评估,把世界模型作为动作规划器进行评估;三是关注策略评估可靠性,评测基于世界模型的评估是否能如实预测真实世界的策略表现;四是关于下游数据的扩展性,衡量合成的交互数据对于下游策略模型学习的支持作用。
研究还系统指出了该领域面临的六大核心挑战,包括高效数据采集、因果结构与物理约束的嵌入、评估基准的构建、与大语言模型的融合、实际部署中的安全与效率问题,以及跨尺度统一物理世界模型的实现,为该领域的未来研究提供了重要方向指引。